> If we had RS(6:3:3) 6 data chunks, 3 coding chunks, 3 local chunks, the following rule could be used to spread it over 3 datacenters:
>
> rule erasure_ruleset {
> ruleset 1
> type erasure
> min_size 3
> max_size 20
> step set_chooseleaf_tries 5
> step take root
> step choose indep 3 type datacenter
> step choose indep 4 type device
> step emit
> }
>
> crushtool -o /tmp/t.map --num_osds 500 --build node straw 10 datacenter straw 10 root straw 0
> crushtool -d /tmp/t.map -o /tmp/t.txt # edit the ruleset as above
> crushtool -c /tmp/t.txt -o /tmp/t.map ; crushtool -i /tmp/t.map --show-bad-mappings --show-statistics --test --rule 1 --x 1 --num-rep 12
> rule 1 (erasure_ruleset), x = 1..1, numrep = 12..12
> CRUSH rule 1 x 1 [399,344,343,321,51,78,9,12,274,263,270,213]
> rule 1 (erasure_ruleset) num_rep 12 result size == 12: 1/1
>
> 399 is in datacenter 3, node 9, device 9 etc. It shows that the first four are in datacenter 3, the next in datacenter zero and the last four in datacenter 2.
>
> If the function calculating erasure code spreads local chunks evenly ( 321, 12, 213 for instance ), they will effectively be located as you suggest. Andreas may have a different view on this question though.
>
> In case 78 goes missing ( and assuming all other chunks are good ), it can be rebuilt with 512, 9, 12 only. However, if the primary driving the reconstruction is 270, data will need to cross datacenter boundaries. Would it be cheaper to elect a primary closest ( in the sense of get_common_ancestor_distance https://github.com/ceph/ceph/blob/master/src/crush/CrushWrapper.h#L487 ) to the OSD to be recovered ? Only Sam or David could give you an authoritative answer.
That scheme does work out, except I'm not sure how the
recovering/remapped OSD can makes sure to read the local copies. I'll
wait to hear what Sam and David have to say. That said, what do you
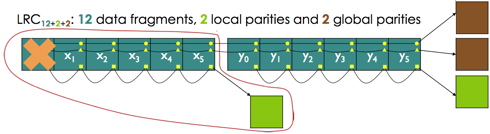
think of this diagram of a 12,2,2:
http://storagemojo.com/wp-content/uploads/2012/09/LRC_parity.PNG from [4]
With a 12,2,2 LRC code the stripe is split into 12 units, those 12
units are used to generate 2 global parity units. The original 12
units are then split into 2 groups, and each group separately
generates an additional local parity unit. Each group of 6 original
units and 1 parity unit are passed through CRUSH for placement with a
common ancestor (for local recovery). This would be low overhead,
certainly less than a replicated, and be friendlier on inter-dc links
during remapping and recovery.
[4] http://storagemojo.com/2012/09/26/more-efficient-erasure-coding-in-windows-azure-storage/
--
Kyle Bader - Inktank
Senior Solution Architect
--
To unsubscribe from this list: send the line "unsubscribe ceph-devel" in
the body of a message to majordomo@xxxxxxxxxxxxxxx
More majordomo info at http://vger.kernel.org/majordomo-info.html
{kind=link}
