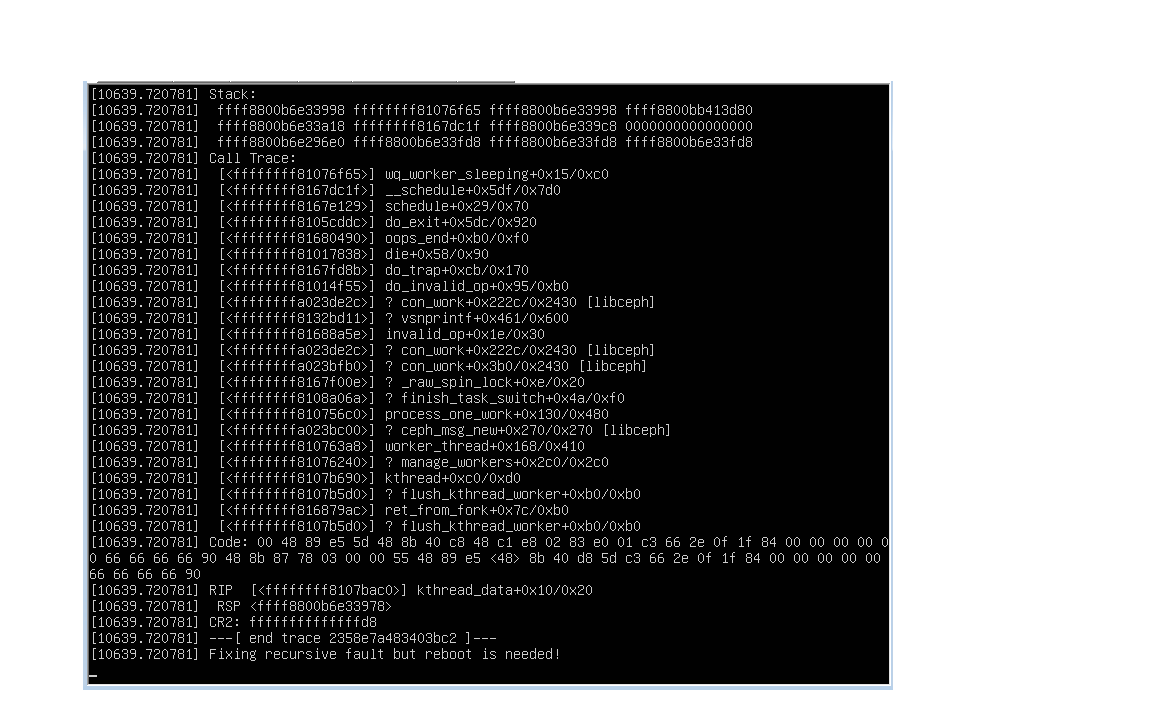
2012/12/20 Alex Elder <elder@xxxxxxxxxxx>: > On 12/19/2012 05:17 PM, Ugis wrote: >> Hi all, >> >> I have been struggling to map ceph rbd images for last week, but >> constantly get kernel crashes. >> >> What has been done: >> Previously we had v0.48 set up as test cluster(4 hosts, 5 osds, 3 >> mons, 3 mds, custom crushmap) on Ubuntu 12.04 and client Ubuntu >> Precise for mapping rbd+iscsi export, can't remember exact kernel >> version when crashes appeared. At some point it was no longer possible >> to map rbd images - on command "rbd map..." machine just crashed with >> lots of dumped info on screen. Same rbd map commands that worked >> before started to crash kernel at some point. > > We'll want to get some of this detail to try to understand > exactly what's going on. > >> I red some advices on list to use kernels 3.4.20. or 3.6.7. as those >> should have all known rbd module bugs fixed. I used one of those(I >> believe 3.6.7.) and managed to map rbd images again for couple of >> days. Then I discovered slow disk I/O on one host and removed OSD from >> it and moved that OSD to other new host(following doc.). For time of >> doing this rbd images were mapped. As I was busy moving osd I didn't >> notice moment when client crashed again, but I think that was some >> time after cluster had already recovered from degraded state after >> adding new osd. > > OK. This is good to know. > >> After this point I could not map rbd images from client no more - on >> command "rbd map..." system just crashed. Reboots after crash did not >> help. >> I installed fresh Ubuntu Precise+3.6.7. kernel on spare box, crushes >> remained, then set up VM with Ubuntu Precise + tried kernels mentioned >> below and still got 100% crashes on "rbd map..." command. > >> Well, those are blurry memories of problem history, but during last >> days I tried to solve problem by updating all possible components - it >> did not help neither unfortunately. >> >> What I have tried: >> I completely removed demo cluster data(dd over osd data partitions, >> journal partitions, rm for rest files, purged+upgraded ceph packages >> to ceph version 0.55.1(8e25c8d984f9258644389a18997ec6bdef8e056b)) as >> update was planned anyway. So ceph is now 0.55.1 on Ubuntu 12.04+xfs >> for osds. >> Then I compiled kernels 3.4.20, 3.4.24, 3.6.7, 3.7.1 for client and >> tried to map rbd image - constant crash with all versions. > > Let's try to narrow down the scope to just one version. Let's > go with the 3.7.1 kernel you're using. Is it the stock version > of that code, with commit id cc8605070a? > Ok, I'm running client on VM now, Ubuntu precise + 3.7.1 kernel. # uname -a Linux ceph-gw4 3.7.1 #1 SMP Wed Dec 19 17:27:13 EET 2012 x86_64 x86_64 x86_64 GNU/Linux Well, where can I find commit id on running system? Here is how I set up kernel to make sure this is not the spot that has been done wrong: 1) downloaded from http://www.kernel.org/pub/linux/kernel/v3.0/linux-3.7.1.tar.bz2 2) unpacked, run "make menuconfig" staying with defaults, made sure ceph and rbd related modules are in(here excerpt from config post .deb install) # grep -i -E 'rbd|ceph' /boot/config-3.7.1 CONFIG_CEPH_LIB=m # CONFIG_CEPH_LIB_PRETTYDEBUG is not set CONFIG_CEPH_LIB_USE_DNS_RESOLVER=y CONFIG_BLK_DEV_DRBD=m # CONFIG_DRBD_FAULT_INJECTION is not set CONFIG_BLK_DEV_RBD=m CONFIG_CEPH_FS=m 3) followed "Debian method" instructions at http://mitchtech.net/compile-linux-kernel-on-ubuntu-12-04-lts-detailed/ to gain .deb packages for using on other hosts later. All went well and I installed 3.7.1 from produced .deb packages Just in case this helps here follows current version of loaded module. # modinfo rbd filename: /lib/modules/3.7.1/kernel/drivers/block/rbd.ko license: GPL author: Jeff Garzik <jeff@xxxxxxxxxx> description: rados block device author: Yehuda Sadeh <yehuda@xxxxxxxxxxxxxxx> author: Sage Weil <sage@xxxxxxxxxxxx> srcversion: F874FF78BD85BA3CF47724C depends: libceph intree: Y vermagic: 3.7.1 SMP mod_unload modversions >> Interesting part about map command itself - as I installed new rbd >> client box and VM I copy/pasted "rbd map.." commands that worked at >> very beginning to these machines. > > Are the crashes you are seeing happening in the VM guest, > or in the host, or both? Here too I'd like to work with > just one environment, to avoid confusion. Whichever is > easiest for you works fine for me. > Just guest crashes. After VM has crashed, virtualization platform shows that VM is still in running state, but cpu utilization is high. I have attached screenshot of crushed VM(console view). Virtualization is OracleVM, xen based, if that helps. >> Command was "rbd map fileserver/testimage -k /etc/ceph/ceph.keyring", >> but this command still crashes kernel even now when there is no rbd >> "testimage"(I recreated pool "fileserver"). >> Crash happens on command "rbd map notexistantpool/testimage -k >> /etc/ceph/ceph.keyring" as well. Could that be some issue with >> backward compatibility as mapping like this was done on versions ago. >> >> Then I decided to try different mapping syntax. Some intro+results: >> # rados lspools >> data >> metadata >> rbd >> fileserver >> >> # rbd ls -l >> NAME SIZE PARENT FMT PROT LOCK >> testimage1_10G 10000M 1 >> >> # rbd ls -l --pool fileserver >> rbd: pool fileserver doesn't contain rbd images > > Normally the pool name is "rbd" for rbd images. > Unless you specified something different you can > just use "rbd", or don't specify it. I.e.: > > # rbd ls -l > or > # rbd ls -l --pool rbd > >> well, I do not understand what in doc >> (http://ceph.com/docs/master/rbd/rbd-ko/) is meant by "myimage" so I >> am ommiting that part, but in no way kernel should crash if wrongly >> passed command has been given. >> Excerpt from doc: >> sudo rbd map foo --pool rbd myimage --id admin --keyring /path/to/keyring >> sudo rbd map foo --pool rbd myimage --id admin --keyfile /path/to/file >> Anyone can explain what is "foo" and "myimage" meaning here? Wich one is image name in pool and what is the other for? >> My commands: >> "rbd map testimage1_10G --pool rbd --id admin --keyring >> /etc/ceph/ceph.keyring" -> crash >> "rbd map testimage1_10G --pool rbd --id admin --keyfile >> /tmp/secret"(only key extracted from keyring and writen to >> /tmp/secret) -> crash >> >> As crashes happen in client side and are immediate - I have no logs >> about it. I can post screenshots from console when crash happens, but >> they all are almost the same, containing strings: >> "Stack: ... >> Call Trace:... > > This is the stuff I want to see. A screenshot, if readable, > would be just fine, but if you can extract the information > in text form it would be best. > Please find screenshot attached. Sorry, had no good text recognition tools available. Online tools provided poor results. > Also, if you can provide information about your configuration, > how many osd's, etc. (or your ceph.conf file). > ceph.conf included below text. osds 1,3 journal in journal file on same disk as ceph data osds 0,2,4 journal to LV on SSD (host ceph2 = 1 SSD for journals + 3 HDD for data), but probably that is not related to client crash.. >> Fixing recursive fault but reboot is needed!" >> >> Also, when VM crashes - virtualization still shows high CPU >> load(probably some loop?) >> I tried default and custom CRUSH maps, but crashes are the same. >> >> If anyone could advice how to get out of this magic compile >> kernel->"rbd map.."->crash cycle - I would be happy :) >> Probaby someone can reproduce crashes with similar commands? If I can >> send any additional valuable info to track down the problem - please >> let me know what is needed. >> >> BR, >> Ugis > > With a little more information it'll be easier to try to > explain what's going wrong. We'll hopefully get you going > again and with any luck also be sure nobody has similar problems. > > -Alex > >> To unsubscribe from this list: send the line "unsubscribe ceph-devel" in >> the body of a message to majordomo@xxxxxxxxxxxxxxx >> More majordomo info at http://vger.kernel.org/majordomo-info.html >> > ceph.conf ----- [global] auth supported = cephx auth cluster required = cephx auth service required = cephx auth client required = cephx cephx require signatures = true [osd] osd journal size = 10000 [mon] mon clock drift allowed = 1 [mds] [mon.1] host = ceph1 mon addr = 10.3.3.1:6789 [mon.2] host = ceph2 mon addr = 10.3.3.2:6789 [mon.3] host = ceph3 mon addr = 10.3.3.3:6789 [mds.1] host = ceph1 [mds.2] host = ceph2 [mds.3] host = ceph3 [osd.0] host = ceph2 osd journal = /dev/VG-system/for-sdb osd journal size = 0 [osd.1] host = ceph1 [osd.2] host = ceph2 osd journal = /dev/VG-system/for-sdd osd journal size = 0 [osd.3] host = ceph4 [osd.4] host = ceph2 osd journal = /dev/VG-system/for-sdc osd journal size = 0 ---- # ceph -s health HEALTH_OK monmap e1: 3 mons at {1=10.3.3.1:6789/0,2=10.3.3.2:6789/0,3=10.3.3.3:6789/0}, election epoch 4, quorum 0,1,2 1,2,3 osdmap e22: 5 osds: 5 up, 5 in pgmap v763: 1160 pgs: 1160 active+clean; 8872 bytes data, 20187 MB used, 8157 GB / 8177 GB avail mdsmap e6: 1/1/1 up {0=3=up:active}, 2 up:standby Ugis
Attachment:
vm-crash.png
Description: PNG image

{kind=link}