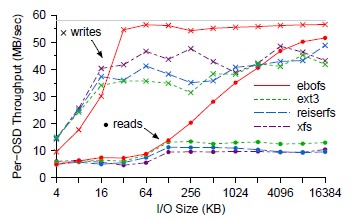
2011/5/9 Gregory Farnum <gregf@xxxxxxxxxxxxxxx>: > On Sun, May 8, 2011 at 8:04 PM, Simon Tian <aixt2006@xxxxxxxxx> wrote: >> For primary copy, I think when the replication size is 3, 4, or even >> more, the writing speed should also near with 2 replication. Because >> the 2nd, 3rd, 4th, ... replication are written parallelly. ÂThe speed >> I got for 3, 4 replication is not near with the speed of 2, in fact, >> like linear reduce. > You're hitting your network limits there. With primary copy then the > primary needs to send out the data to each of the replicas, which caps > the write speed at (network bandwidth) / (num replicas). Presumably > you're using a gigabit network (or at least your nodes have gigabit > connections): > 1 replica: ~125MB/s (really a bit less due to protocol overhead) > 2 replicas:~62MB/s > 3 replicas: ~40MB/s > 4 replicas: ~31MB/s > etc. > Of course, you can also be limited by the speed of your disks (don't > forget to take journaling into account); and your situation is further > complicated by having multiple daemons per physical node. But I > suspect you get the idea. :) Yes, you are very right! The client throughput with different replication size will be limited by the network bandwidth of the primary copy. I have some other questions: 1. If I have to write or read a sparse file randomly, will the performance reduce much? 2. Is a rbd image sparse file? 3. As the attachment showed, the read throughput will increase when I/O size increasing. What is this I/O size mean? Is there any relationship between I/O size and object size? In the latest ceph, what will the read throughput of different file system like with different I/O size? Thx very much! Simon
Attachment:
fs_throughput.jpg
Description: JPEG image

{kind=link}