I'm in the process of adding monitoring support to dmix (i.e. the
ability for applications to capture the sound being played back through
the speakers) - expect patches for this soon. However while reading the
dmix source code I came across something weird. Dmix uses a lock-free
mixing implementation based on (architecture-dependent) atomic
operations such as atomic addition and compare-exchange. However at the
same time dmix also uses a semaphore to prevent multiple processes from
accessing the shared memory buffers simultaneously. This is redundant
and makes the lock-free implementation rather pointless.
Out of curiosity I decided to measure the time it takes to execute
snd_pcm_dmix_sync_area for these three cases:
- A simple locked implementation, which acquires the semaphore and then
does mixing using the non-concurrent code from pcm_dmix_generic.c.
- The current (redundant) implementation, which acquires the semaphore
and then does atomic mixing.
- A lock-free implementation, which does not acquire the semaphore and
does atomic mixing.
The resulting sound is identical in all three cases. (As a sanity check
I also tested the 4th case, non-concurrent code without locking, which
as expected produces audio with glitches.)
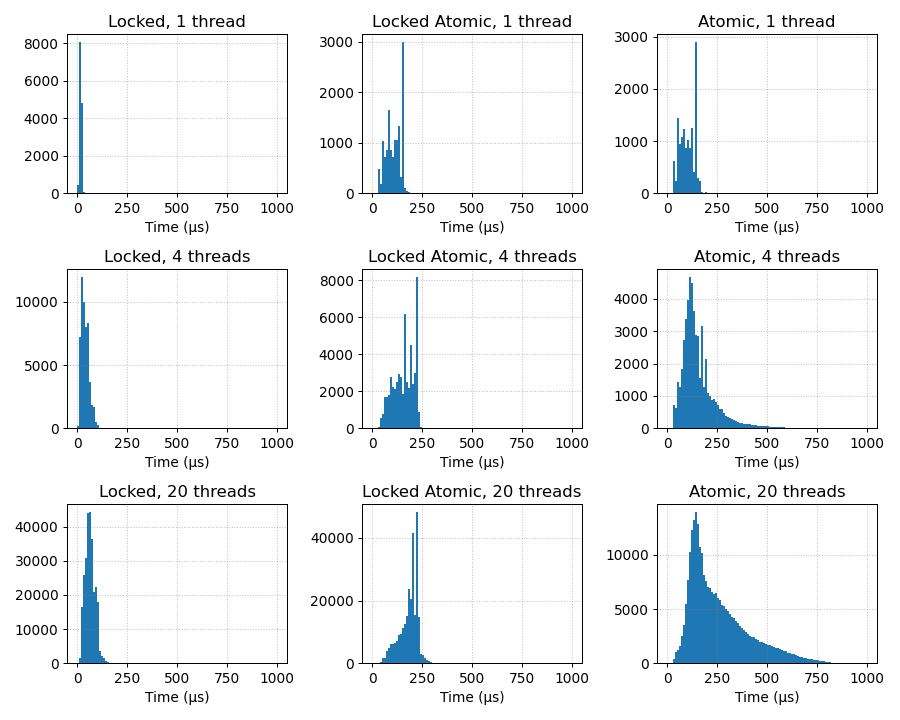
I tested each case with 1, 4 and 20 simultaneous playback streams
(multiple instances of 'aplay') on a system with 4 physical CPU cores
(Intel Core i7-4770). You can see the results here:
https://misc.maartenbaert.be/dmix_perf_locked_atomic.png
The results are quite surprising:
- The locked implementation is 3 to 6 times *faster* than the current
redundant implementation.
- The lock-free implementation is usually about as fast as the current
redundant implementation, but has extreme outliers that are up to 3
times *slower* than the redundant implementation when there are multiple
threads.
It seems that the overhead of the atomic operations is so high that it
completely negates the theoretical advantage of being able to mix from
multiple threads simultaneously. This may be the result of 'false
sharing' when multiple threads are accessing different words in the same
cache line (which is almost impossible to avoid when mixing audio).
On a related note, I believe that I have also found a bug in the
lock-free implementation. The logic which is used to clear the 'sum'
buffer is as follows:
sample = *src;
old_sample = *sum;
if (ARCH_CMPXCHG(dst, 0, 1) == 0)
sample -= old_sample;
ARCH_ADD(sum, sample);
This takes advantage of the fact that the hardware driver clears the
playback buffer after reading it. However it does not account for the
possibility that 'dst' might be zero for other reasons, such as:
- An application plays back silence.
- An application plays back sound, but then rewinds it.
- Multiple applications play back sound which just happens to sum to
zero occasionally.
These all result in situations where 'dst' is changed from 0 to 1 by the
compare-exchange operation, but then changed back to zero later,
resulting in the classic 'ABA problem'. However this problem is
currently hidden by the fact that the lock-free implementation is in
fact still locked.
Because of these reasons I think it would be better to drop the
lock-free implementation entirely and just use the existing
non-concurrent architecture-independent implementation from
pcm_dmix_generic.c. Aside from being faster, it would also eliminate a
lot of architecture-dependent code and inline assembly. Should I submit
a patch for this?
Best regards,
Maarten Baert

{kind=link}