Hi all,
After our catch up, we were discussing performance
matters. I decided to start on this while waiting for some of my
tickets to be reviewed and to see what's going on.
These tests were carried out on a virtual machine
configured in search 6 to have access to 6 CPU's, and search 12
with 12 CPU. Both machines had access to 8GB of ram.
The hardware is an i7 2.2GHz with 6 cores (12
threads) and 32GB of ram, with NVME storage provided.
The rows are the VM CPU's available, and the columns
are the number of threads in nsslapd-threadnumber. No other
variables were changed. The database has 6000 users and 4000
groups. The instance was restarted before each test. The search
was a randomised uid equality test with a single result. I
provided the thread 6 and 12 columns to try to match the VM and
host specs rather than just the traditional base 2 sequence we
see.
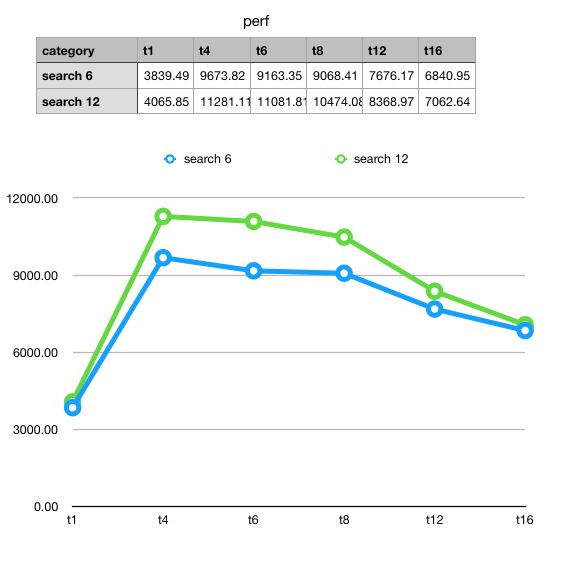
I've attached a screen shot of the results, but I
have some initial thoughts to provide on this. What's
interesting is our initial 1 thread performance and how steeply
it ramps up towards 4 thread. This in mind it's not a linear
increase. Per thread on s6 we go from ~3800 to ~2500 ops per
second, and a similar ratio exists in s12. What is stark is that
after t4 we immediately see a per thread *decline* despite the
greater amount of available computer resources. This indicates
that it is poor locking and thread coordination causing a rapid
decline in performance. This was true on both s6 and s12. The
decline intesifies rapidly once we exceed the CPU avail on the
host (s6 between t6 to t12), but still declines even when we do
have the hardware threads available in s12.
I will perform some testing between t1 and t6
versions to see if I can isolate which functions are having a
growth in time consumption.
For now an early recommendation is that we alter our
default CPU auto-tuning. Currently we use a curve which starts
at 16 threads from 1 to 4 cores, and then tapering down to 512
cores to 512 threads - however in almost all of these autotuned
threads we have threads greater than our core count. This from
this graph would indicate that this decision only hurts our
performance rather than improving it. I suggest we change our
thread autotuning to be 1 to 1 ratio of threads to cores to
prevent over contention on lock resources.
Thanks, more to come once I setup this profiling on
a real machine so I can generate flamegraphs.
—
Sincerely,
William Brown
Senior Software Engineer, 389 Directory Server
SUSE Labs
_______________________________________________
389-devel mailing list -- 389-devel@xxxxxxxxxxxxxxxxxxxxxxx
To unsubscribe send an email to 389-devel-leave@xxxxxxxxxxxxxxxxxxxxxxx
Fedora Code of Conduct: https://docs.fedoraproject.org/en-US/project/code-of-conduct/
List Guidelines: https://fedoraproject.org/wiki/Mailing_list_guidelines
List Archives: https://lists.fedoraproject.org/archives/list/389-devel@xxxxxxxxxxxxxxxxxxxxxxx